作者:谢湘宁
摘要:当代是科学技术迅猛发展的时代,专利信息作为获取技术创新以及商业竞争主动权的情报信息,专利信息的研究成为当务之急。本文将数据挖掘技术应用到专利信息的分析当中,为企业的技术竞争和商业竞争提供有效的措施和手段,使其成为支持企业决策的有效依据。
关键字:专利信息、数据挖掘、决策依据
一、引言
随着当前科学技术和知识经济的飞速发展,企业之间的知识竞争日趋激烈,经研究者发现,企业间的竞争可以通过所拥有的自主知识产权来集中体现,特别是专利的数量和质量的竞争[1]。而在企业拥有了海量的专利之后,如何从海量的专利信息中理性的获取隐含的情报信息,挖掘出专利的潜在价值,使其成为企业决策过程中的有效依据将是一个巨大的挑战。在这样的背景形势之下,专利分析(Patent Analysis)作为一种独特而实用的分析方法,可以为企业提供有效的企业竞争情报[2]。
传统的专利信息的分析方法主要包括原文分析法和数据统计等方法,即通过专利文献上所固有的指标数据(如专利申请号等)来识别相关文献,然后对指标数据进行统计以取得动态发展趋势的分析报告。由于这种传统的分析方法没有建立在专利本身潜藏的知识体系上,因此,面对大量的专利文献数据时,不仅工作量繁巨,而且对专利文献的应用也只停留在表层,导致分析不够透彻。
而数据挖掘技术可以从大量杂乱无章的、无法通过人工进行统计的数据中发掘出潜在的信息,而且还可以通过计算机手段将潜在的关系进行构建,呈献给人们以示规律,因此,数据挖掘技术将是优先考虑的专利分析技术[3]。
本文采用数据挖掘技术来代替现有的传统分析方法,获取海量专利数据中原来无法挖掘到的内容和规律。同时采用合适的模型和参数,真正发挥数据挖掘技术应用在专利分析中的作用[4]。
二、 数据挖掘技术在专利信息分析中的技术与实现
本文章将数据挖掘作为一个专利分析的强有力的工具被引入到专利分析中来,主要通过有效的数学模型来对选择的专利信息的数据进行详细分析和处理,更深层次的对专利信息进行有效的分析和挖掘,从而可以深入、充分而且有效的挖掘出隐藏在大量专利信息背后的重要知识。进一步可以解决例如专利预警和警情分析中存在的问题,例如,在某一个产品进入市场尤其进入国际市场之后,将不可避免遭遇国际知名产品在某一些技术方面的竞争和阻击,通过数据挖掘技术可以针对该产品相关的专利信息进行分析和处理,即挖掘和分析高风险技术的专利情况,从而尽早避免可能发生的侵权争端。
1. 专利信息的来源及分类
本文利用专利数据库平台作为数据采集源,采集相关的专利样本,例如,可以通过专利搜索引擎(例如http://www.soopat.com/)筛选一定数量的、已经公开的发明专利文献。
本文在利用数据挖掘技术对专利文献进行分析之前,可以按照专利文献的分类号对专利文献进行分类。国际专利分类法(IPC) 是目前最为权威、应用最广的专利技术主题标识编码之一,它具有编排合理且通用性好的特点[5]。由于过于细致的IPC分类号对专利文档主题的揭示并不有利,因此,研究者认为采用专利文献的专利小类作为分析基础,例如取专利文献IPC分类号的前4位。
2. 对分类后的专利文献进行数据训练
由于专利文献是文本格式类型的文件,为了能够把数据挖掘技术,例如聚类技术应用到文本格式类型的文献中,需要对文本格式的文献进行数据训练,数据训练用于实现对真实的专利文献进行文本的预处理,包括对专利文献进行分词、关键词训练和提取,以及对关键词的权重计算,其中,关键词训练和提取主要包括词性标注和停用词过滤。
(1)专利信息的分词处理
需要对分类后的专利文献进行分词处理,从而获取到每个专利文献中的若干关键词,专利文献中的这些关键词用于表征当前专利申请的主要核心技术、主要用途的词或短语。
此处需要重点说明的是,由于中文语句的特点是在一句完整的语句中无法通过空格将词汇分割,因此,分词技术主要针对中文文本的专利文献,分词策略可以包括:按照扫描方向的不同可以分为正相匹配和逆向匹配的分词策略;按照字符串的不同长度的优先策略可以分为最大匹配和最小匹配的分词策略;按照是否有词性标注的方式,可以分为单纯分词和分词与标注相结合的分词策略。分词技术可以将文档词汇化,为关键词训练作基础。
而针对英文语句,由于英文单词之间一般采用空格隔开,从而使得英文语句无需进行分词处理,但需要对英文专利文献进行剔除和整合词语的预处理。在英文专利文献中,类似于an、the、that、first等介词、连词、数量词属于没有特殊标注性含义的停用词,在文本挖掘不具备关键术语的特征,因此,在英文专利文献的文本预处理过程中需要剔除停用词。另外,由于英文词汇中某个词语可能存在大量变形和时态的变化,一个词语变形后的多个词汇表征的含义相同或相似,也不具备关键术语的特性,因此,在英文专利文献的文本预处理过程中需要将具有相同或相似含义的词句进行整合。经文本聚类分析领域的一些专家研究发现,文本预处理过程中提取的关键词通常只包括名词或名词性短语的概率较大。
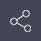
以申请号为200910092794.8的专利为例,如图1所示,系统在自动加载了原始的摘要和用途字段之后,可以自动进行分词处理,提取并显示关键词。
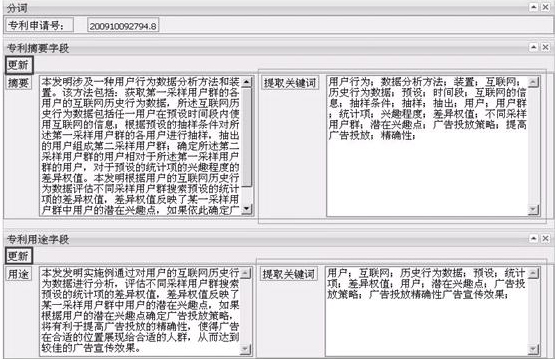
图1 分词界面示意图
(2)关键词训练
为了将专利文献转化为计算机可以处理的信息,需要对分词处理有的专利文献进行关键词训练,关键词训练的主要目的是为了提取有代表性的词汇,以便于生成专利文档的可以表征文档特性的向量,本质上就是将无结构的原始文章进行科学抽象,建立数学模型,用结构化的语言表征文档本身。目前人们通常采用向量空间模型来描述文本,用特征向量来表示文档本身。
由上可知,上述针对专利文献的数据训练过程,通过关键词的频率及权重确定了每篇专利文献的特征向量,实现了对海量的专利文献的分类整理和文本预处理,完成了为每个专利文献为基础的源文档建立唯一的向量表,为后续的聚类功能提供了有效的数据源。
3. 对专利文献构成的源数据进行聚类
本文研究的是如何将根据某一技术领域的专利信息对涉及到的技术进行方向划分,其实也就是聚类。之所以会研究这个问题主要在于两个原因:1) 一个技术领域的专利太多,人们可能关心的仅是某一方向上的关键技术,即需要的仅是一个较小方向范围的内的专利信息,这需要筛选;2) 人们需要判断某一篇专利在一个方向内是否又相似的专利,以防止侵权或者重复申请,因为重复申请是无效的。
总之,通过聚类技术我们可以将一个领域内的专利案技术分类进行划分,同时可以判断出一个专利属于那些个方向,聚焦到一个聚类中分析。
数据挖掘领域常用的聚类技术可以包括如下几种:基本k均值技术、二分k均值技术、基于密度的DBSCAN聚类、模糊聚类和EM聚类等。
本文利用数据挖掘技术中的凝聚层次聚类算法,依据余弦相似度作为聚类合并的依据,对得到的每个专利文献的文档向量来进行聚类,即在对文档向量集合中的每个文档向量进行初始化之后,使得若干个专利文档作为一个簇类,然后通过凝聚层次聚类算法的到需要合并的簇类,最终得到该文档向量集合的簇类结果。
4. 专利信息的聚类分析结果及其布局图。
本文利用上述聚类方法聚类得到的聚类数目,分别作出在该选定数目下的聚类比重图、历史变化图,通过曲线变化和数量对比,从而进一步得到某些方向的专利文献数量趋冷还是趋热,专利方向的变化如何,等等非常具有价值的信息。
以2010、2011、2012公开的关于某搜索引擎产品在数据分析领域的150篇专利为例,如图2所示, 在确定聚类数目为10的情况下,对10个聚类当中的具体每一个簇包含多少篇专利文献进行统计,获取每个聚类当中所包含的专利文献数量。
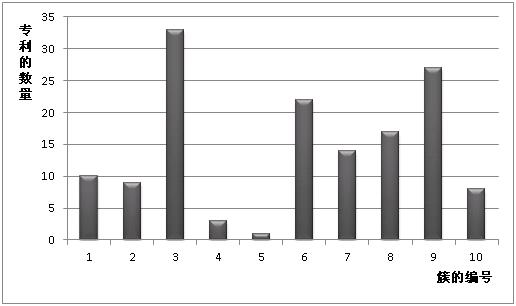
图2基于簇的专利数量总体分布柱形图
分析上图2中的结果,编号为3,6,9的聚类,比较其他聚类专利文献的数据量占比例最大,以上述3个聚类作为考察对象可以直观的确定哪类技术的专利申请量最多,最集中。
分析可知,3,6,9的聚类中的专利技术处于成熟期,这些技术分布范围大,市场占有可能趋于饱和,专利申请量保持稳定;4,5的聚类中的技术处于引入期,该搜索引擎产品的厂商在这些领域技术开发较少,基本属于原理性和基础性的专利;1,2,10的聚类中的专利处于技术发展期,市场在逐步扩大,数量应该是继续增长。
基于此可知,如果该搜索引擎厂商在进军中国市场,例如,研发、销售搜索技术类产品时,可以根据上述分析结果做出以下对策:主要针对发展期的的专利产品进行大力改进和开发,针对成熟期的产品则可以持保守态度,需要时可以采用向对方进行技术许可的策略。
同时,可以针对聚类结果进行更加深入的聚类评估,评估的目的在于判断数据集合是否存在于某聚类中和聚类数量的确定,企业可以利用评估结果解决如下疑惑:
1)利用凝聚度来确定专利文献构成的专利技术在各个自然年的专利数量分布情况。
仍旧以上述2010、2011、2012公开的关于某搜索引擎产品在数据分析领域的150篇专利为例,如图3所示,统计上述3年中,专利数量在3个主要聚类当中的所占数量。
图3每个聚类的专利数量对比柱形图
分析可知,2011 是专利总数量最多的一年,并且2010年的专利数量也保持较高的水平 ,说明2011和2010年的总体专利数量集中在当前的3大聚类当中。
由于上述簇类3、6、9中的专利可以认为是该搜索引擎产品在数据分析领域的重点专利,根据图3的分析结果,簇类6中的专利在逐年减少,可以推测该类技术可能在2013年进入饱和期,这类技术快要被淘汰;簇类3和9中的专利在2010年到2011年大幅增加,但到2012年大幅减少,可以说明这类专利从快速成长期到稳定成熟期的阶段。
2) 利用分离度来确定几个簇类之间的关联度,从而确定对于海量专利文献如何将他们按照内部特征进行分离,以供挖掘出一些潜在信息,例如,比对任意两个或多个自然年,分析得出针对同一个技术领域的研发能力哪一个自然年的研发技术明显更强。
仍旧以上述2010、2011、2012公开的关于某搜索引擎产品在数据分析领域的150篇专利为例,如图4所示的聚类比例历史变化图对应的统计图, 研究每个自然年中那个聚类的热度。
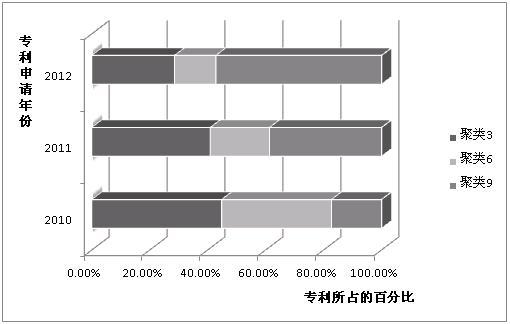
图4聚类后专利比例变化的统计图
分析可知,2010、2011年聚类3的比例最大,2012年聚类9的比例最大,由此我们能够知道,在3个大的聚类当中:聚类3是2010、2011年的最热门方向,聚类9是2012年的最热门方向。
3) 为了进一步的发掘3个聚类内部的趋冷趋热程度,可以将比例变为纵坐标,年份作为横坐标,做出如图5所示的聚类趋势变化图。
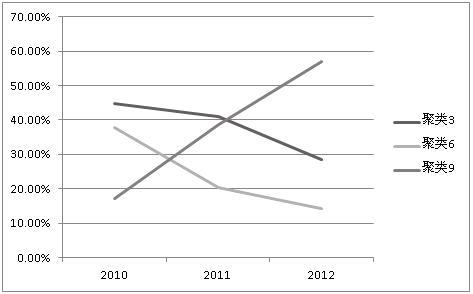
图5聚类趋势变化图
结合图5分析可知:
聚类3从2010年开始,逐年申请的专利在比例上较为持平,下降并不明显,说明该方向技术研究及开发的热度具有一定的持续性。
聚类6从2010年开始,逐年申请的专利在比例下降得比较明显,说明该方向的技术研究及开发的热度在趋于变冷。
聚类9从2010年开始,逐年申请的专利在比例上上升得非常明显,说明该方向的技术研究及开发的热度在趋于变热。
由此可知,利用聚类评估技术作为聚类处理的方法,其主要目标是要在海量专利数据中挖掘潜在的、未知的类别体系。
上述分析过程还可以进一步扩大到对多家竞争企业的专利进行分析,可以获取哪些公司的专利布局最早出现、在哪些年份专利申请量最多、专利申请量是阶梯式增长还是减少等信息,然后进行比较,从而得到整个行业的技术发展的分析结果,例如,在搜索领域哪些技术是核心技术,哪些是被淘汰的技术,哪些技术有更大的发展空间和投资空间等。
三、结语
本文的分析结果是具有实际意义的,对企业进行侵权分析建议(无效、许可、公众意见和专利规避)、竞争对手跟踪建议、市场定位建议等方面都具有实际意义。由于是从专利文献的词汇本身进行分析得到的结果,因此,作者认为本文章的方法比现有的方法分析结果更准确、指导性更强。
参考文献
[1] 于和琴,专利情报数据挖掘-企业获取竞争优势的法宝,商业现代化,2008年5月.
[2] 黄庆,曹津燕,瞿卫军,刘洋,石昱,肖云鹏,专利评价指标体系的设计和构建,知识产权,2003.
[3] 岑咏华,王曰芬,王晓蓉,面向企业技术创新决策的专利数据玩家研究综述,情报理论与实践,第33卷,2010年第1期.
[4] 柴明亮,关联规则在时间序列数据挖掘中的应用[D],北京:北京工业大学,2006:23-24.
[5] 刘德馨,李有馥,国际专利分类法评价[J],情报科学,1993年04期.